

I spoke at the recent PechaKucha on “How to replace A.I. before it replaces you“. To demonstrate how smart the machine learning algorithm we have today, I gave an example that we can easily train a machine learning model to differentiate different types of chicken rice (A typical Malaysian / Singaporean favorite cuisine).
Many participants contacted me right after the event and asked questions like:
- Is that real? Can we really train machine models to recognize chicken rice?
- Other than chicken rice, can I use it for other use cases?
- How does Machine Learning with images work?
That’s the background of this tutorial. I will show you step-by-step how to train a machine learning model, using computer vision, to recognize chicken rice. Before that, we need the following items:
- Set of chicken rice images
- Ground truth (to label the roasted and steamed class)
- A Google Cloud Platform, GCP account (for us to use Google AutoML Vision cloud service.)
The original idea came from this blog post.
I will try to closely follow his methodology as closely and add extra pointers to make it easier for you to follow. I included details such as scrapper and labeled training data to make the work reproducible so that you can try it yourself.
I believe that I can’t share the labeled training data with images due to Instagram’s restriction. But you may get the filename and its respective class from the file here.
Watch the entire tutorial above. Prefer to read? Just continue below.
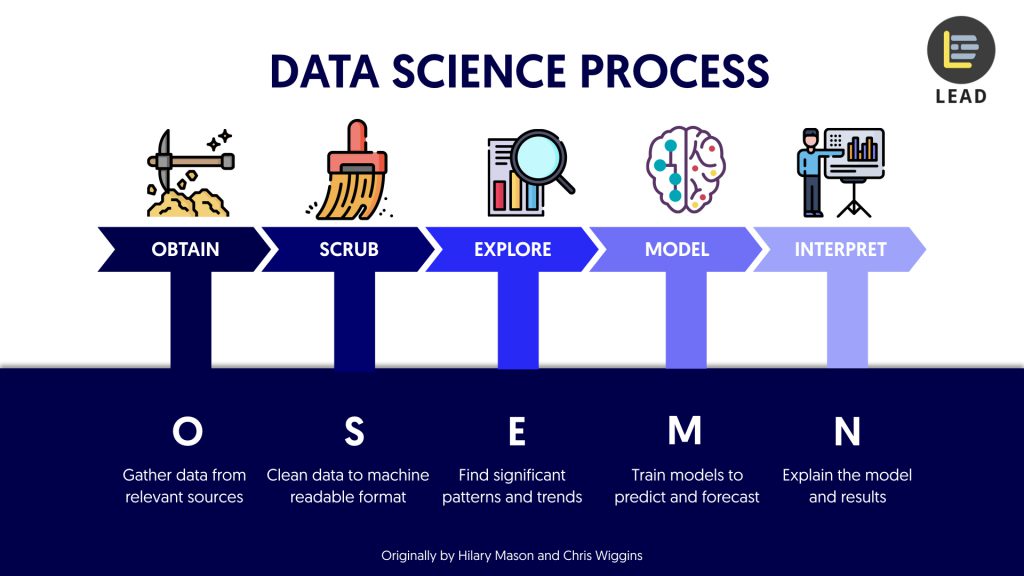
The O.S.E.M.N. Framework
Let’s follow the 5-step OSEMN framework to guide us through the process.
The OSEMN framework is designed to help us focus and prioritize the right data science tasks at different stages.
Step 1: Obtain Data
We will need to find chicken rice images as our training data set.
Luckily for us, there is a Singaporean guy who eats chicken rice every day (454 days consecutively at the time of writing) and posts photos of it to his Instagram account @kuey.png.
{kind=link}
Kuey Png literally means chicken rice in Hokkien.
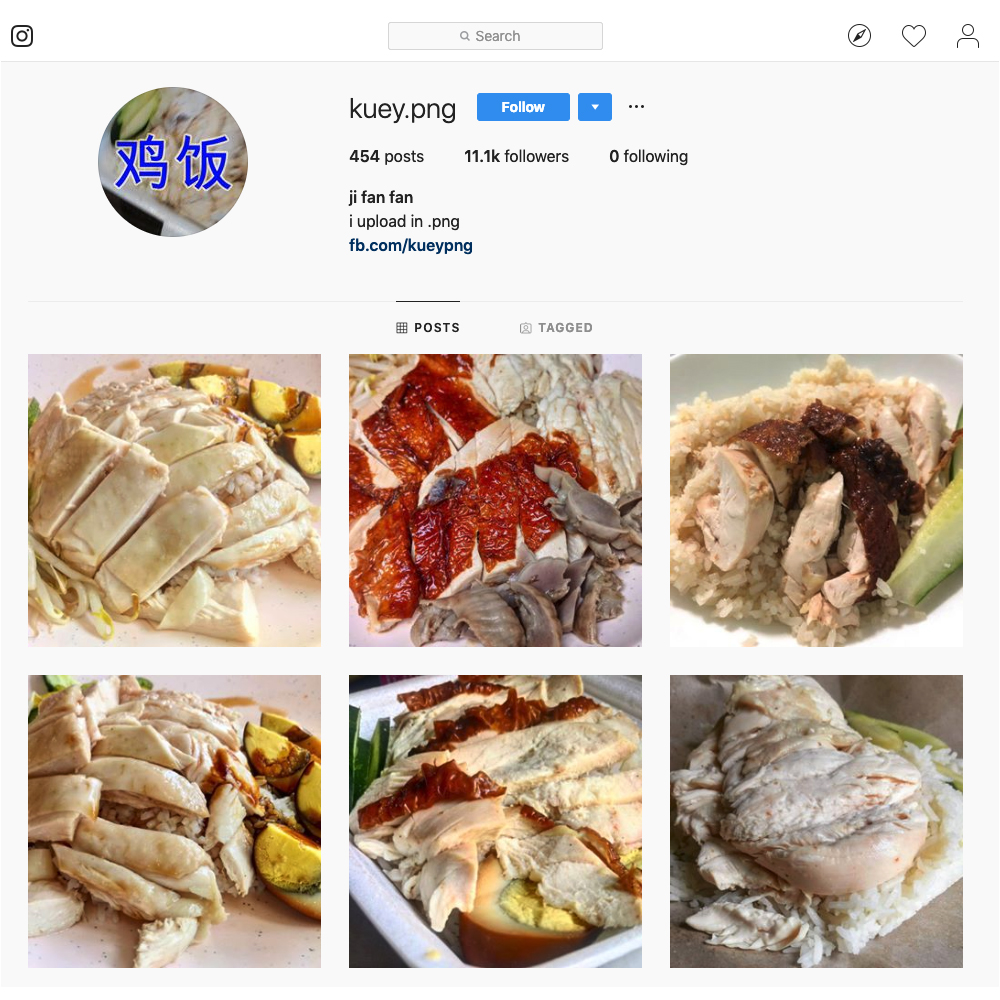
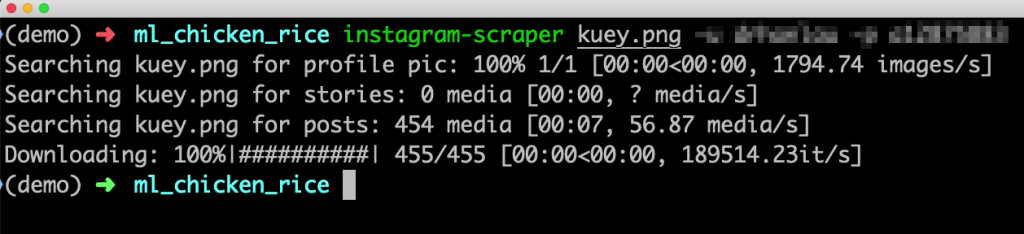
You can then use a scraper to download all the images into your local computer. I used the Python version from https://github.com/rarcega/instagram-scraper. Don’t forget to include the -u <username> and -p <password> at the end (the part where I have mosaicked).
Step 2: Scrub Data
Data never come clean, even in such a focused dataset with so many well-taken photos. While most of the pictures were alright, you’ll come across photos like the one below – which in fact, wasn’t too hard to tell if it’s a packet of steam chicken rice.

The real challenge came for the special cases, where we had to exclude the following images from our training sets because our experts are unable to arrive at a conclusion.

We also exclude 7 photos of braised chicken (another way of cooking chicken). As they are neither steamed nor roasted chicken. Also, there were insufficient training images for us to classify it as a separate class.

Step 3: Explore Data
Before we explore our data, we will need to label the images and create ground truth. In a data science project, the term “ground truth” refers to the process of gathering the proper objective data.
In image classification tasks, ground truth refers to the training classification that we labeled manually, for supervised learning.
Following a benchmark, we engaged 3 people from our team as the experts, who know enough about chicken rice types to label the images. We will only use an image when the 3 experts agreed on the label unanimously.

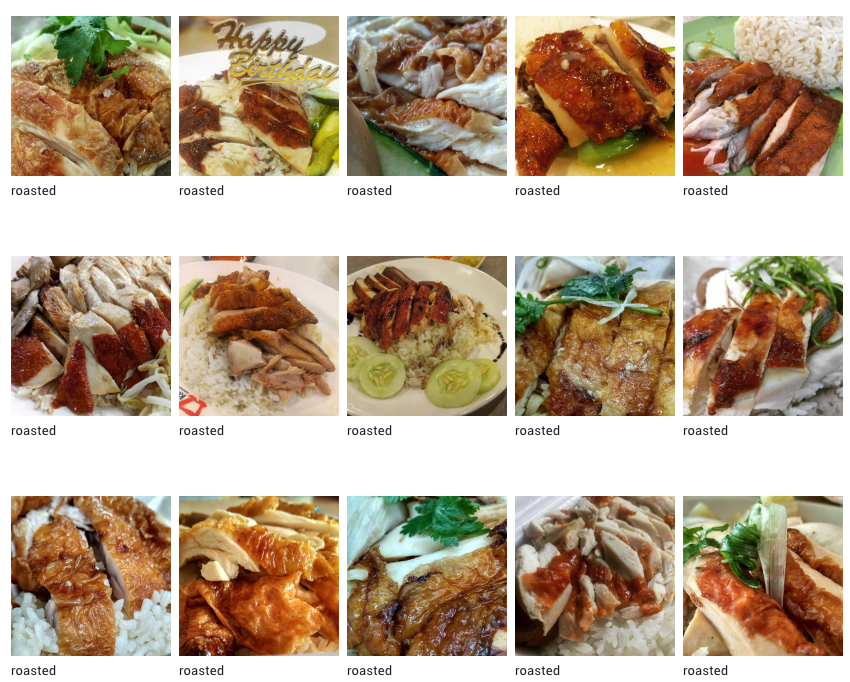
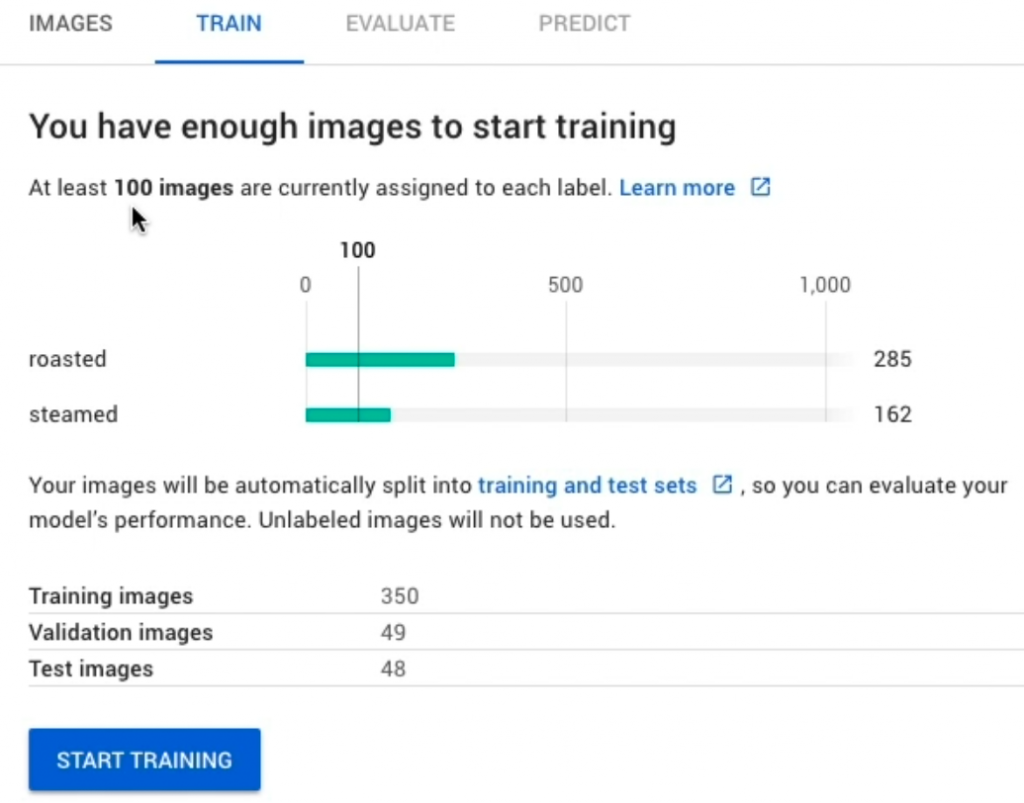
After the labeling process, our training data contains 447 training images. We labeled 285 images as roasted chicken (63%), and 162 images as steamed chicken (37%).
Images that labelers were unable to come to a common agreement on were discarded, along with the pictures of braised chicken. We may add “braised chicken” as another class in the future, when there are more training images.
Step 4: Model Data
If you have read till here, this is the part that you have been waiting for. The modeling stage.
I am going to show you the exact steps of how I did it using Google AutoML Vision. First of all, you need to set up a Google cloud account.
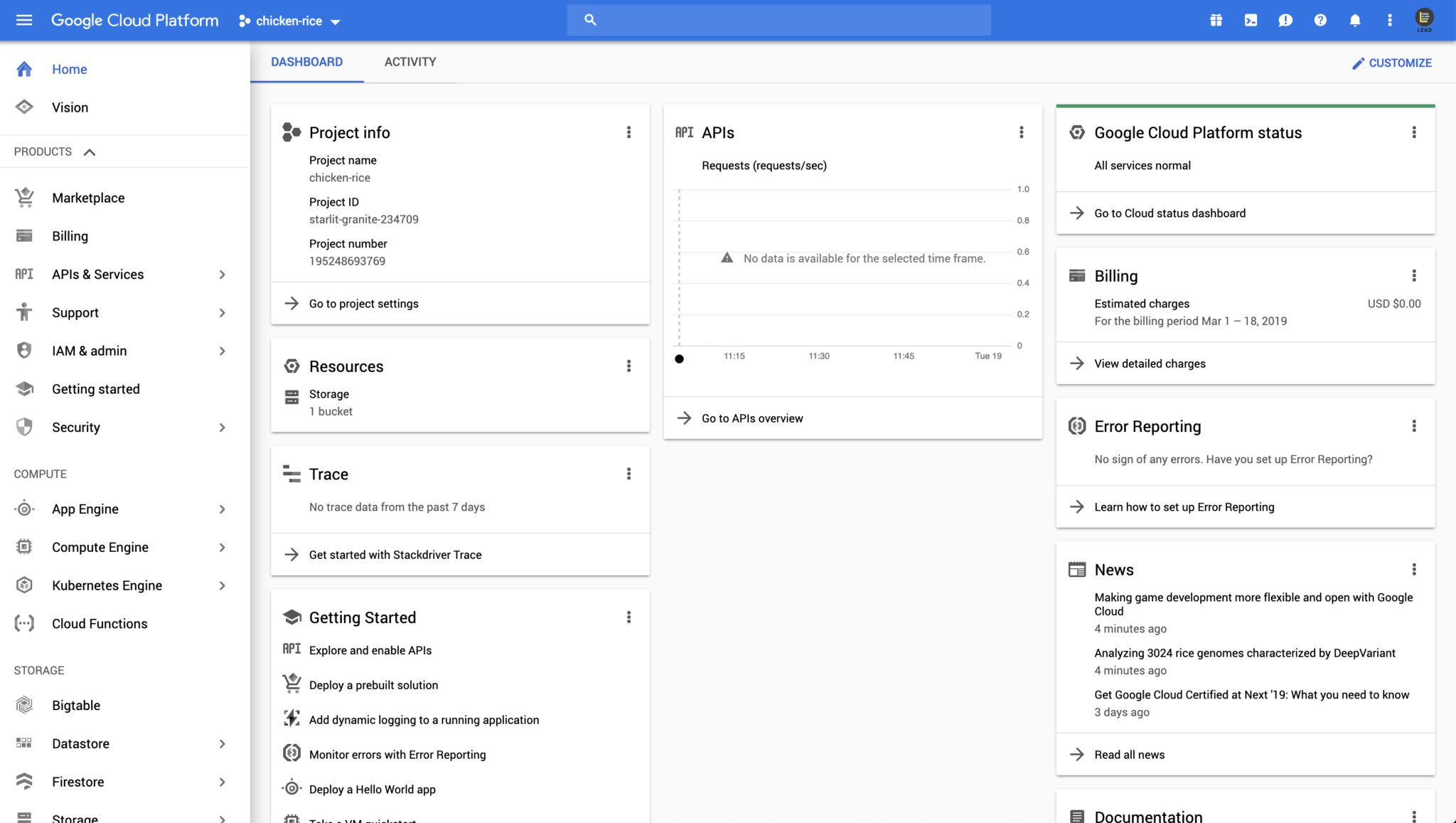
Create a new project, Select Vision at from the menu bar on the left, and create a custom model by clicking “Get started with AutoML“. Setup the billing information accordingly.
Don’t worry about getting charged with your credit card details, Google promised that they will seek for your permission before charging your credit card. Then, click on “setup now” and wait for the process to be completed.
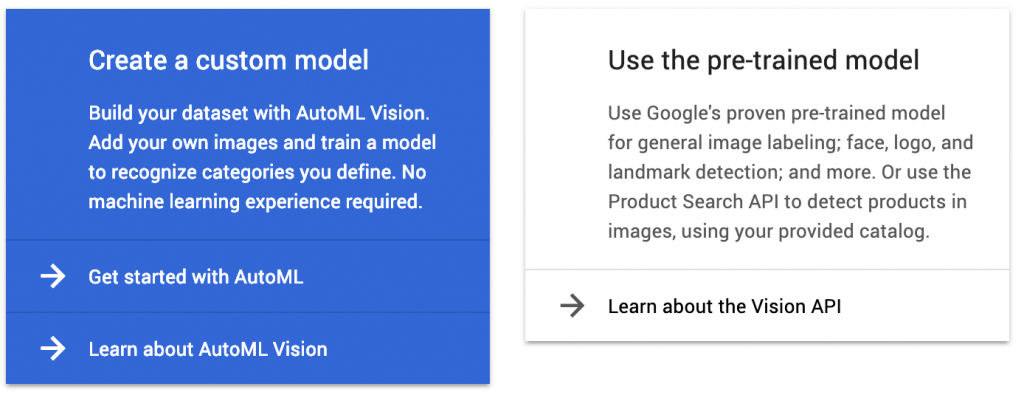
Then, click “create dataset” to create a new dataset to store our chicken rice images. Select “import images later” as we will upload two batches of chicken rice images ourselves, and select “enable multi-label classification”.
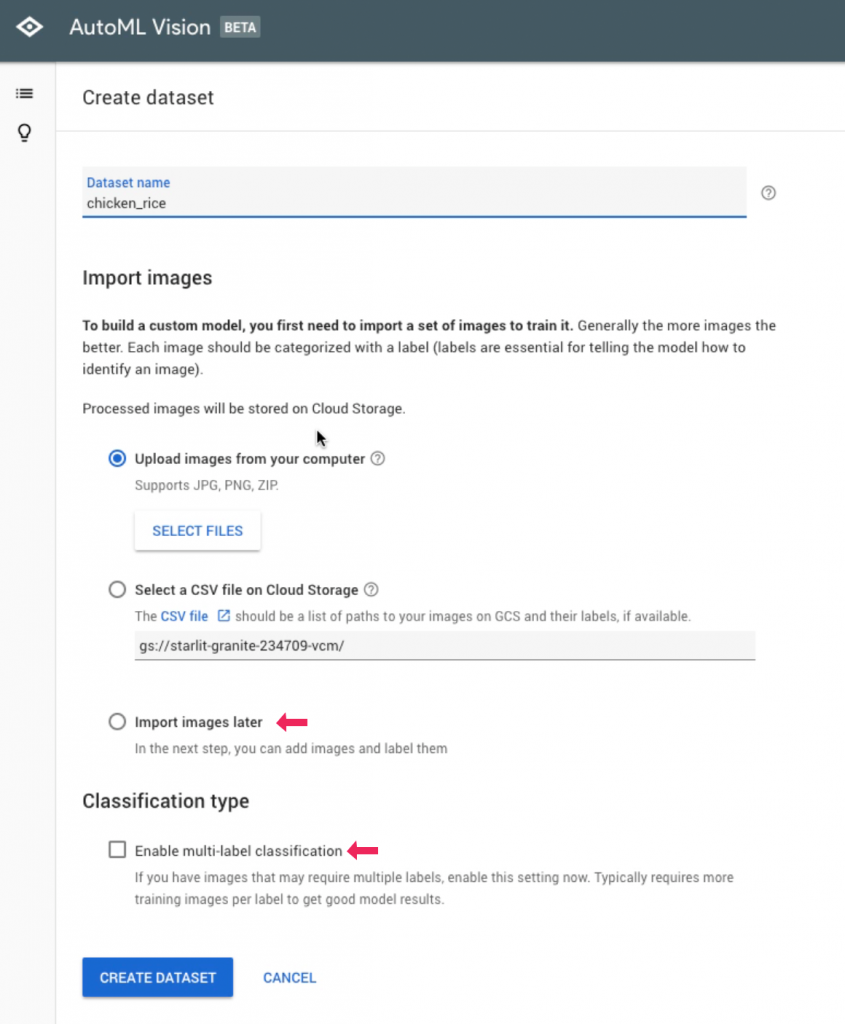
Before we upload our images, let’s create two labels, namely: steamed and roasted. Click “add images” to upload our training image to AutoML Vision.
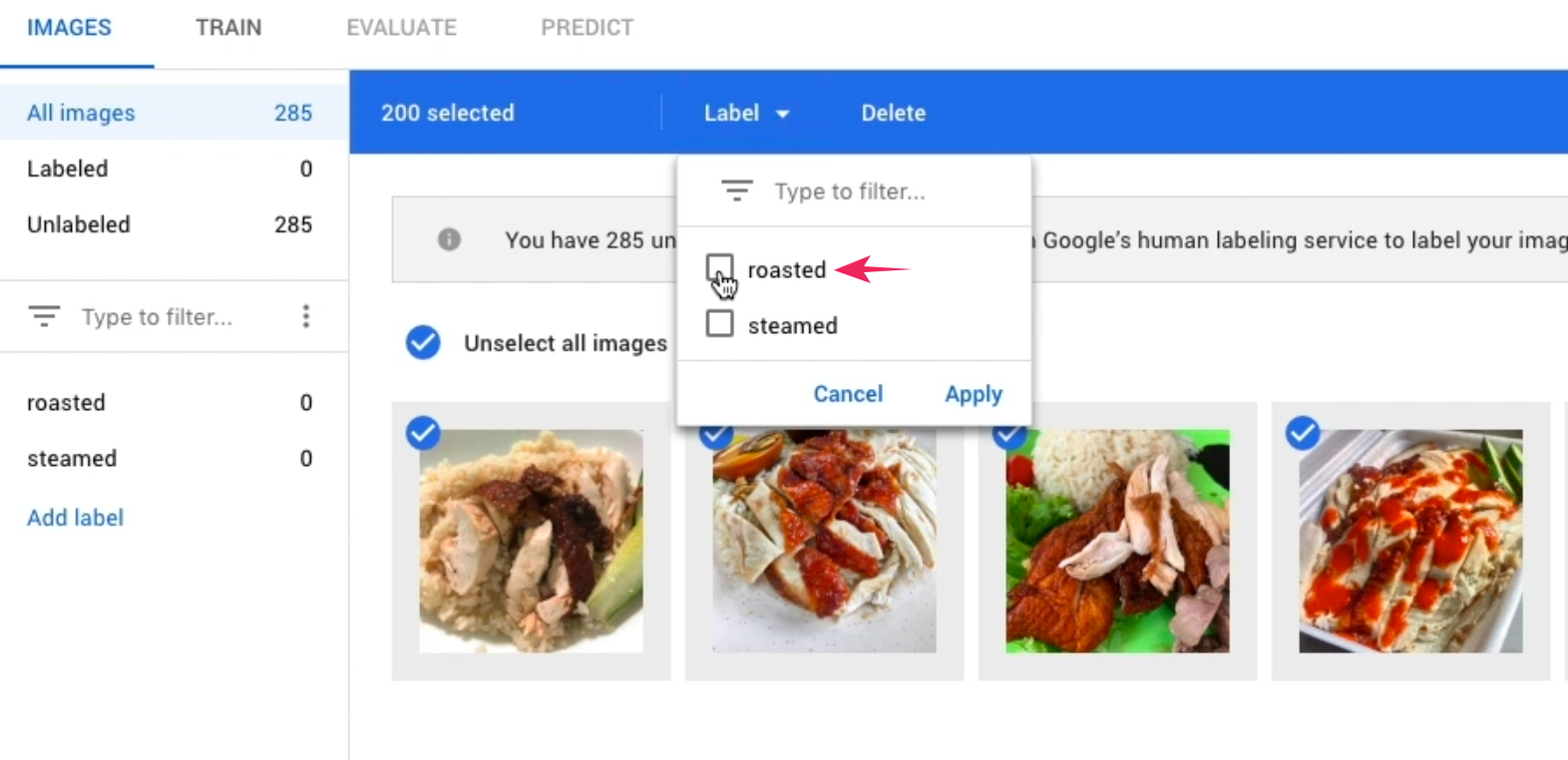
After that, upload the images of roasted chicken. Make sure to label “roasted” for the images as shown in the screenshot below. And repeat the same process for steamed chicken images as well.
Once we have uploaded and labeled our training data, we may proceed to train the model. AutoML vision requires at least 100 images for each label.
Therefore we can only include braised chicken images when we have more training data (Keep up with the good work, sir). Click “start training” and wait for about 15 – 20 minutes to build our model. You will receive an email notification once the training process is completed.
Step 5: Interpret model
AutoML simplifies many modelling tasks and even evaluation that would take data scientists a couple of hours. Click “See Full Evaluation” and let’s take a look at the performance of our model. (Do note that your result might vary when constructing your own model).
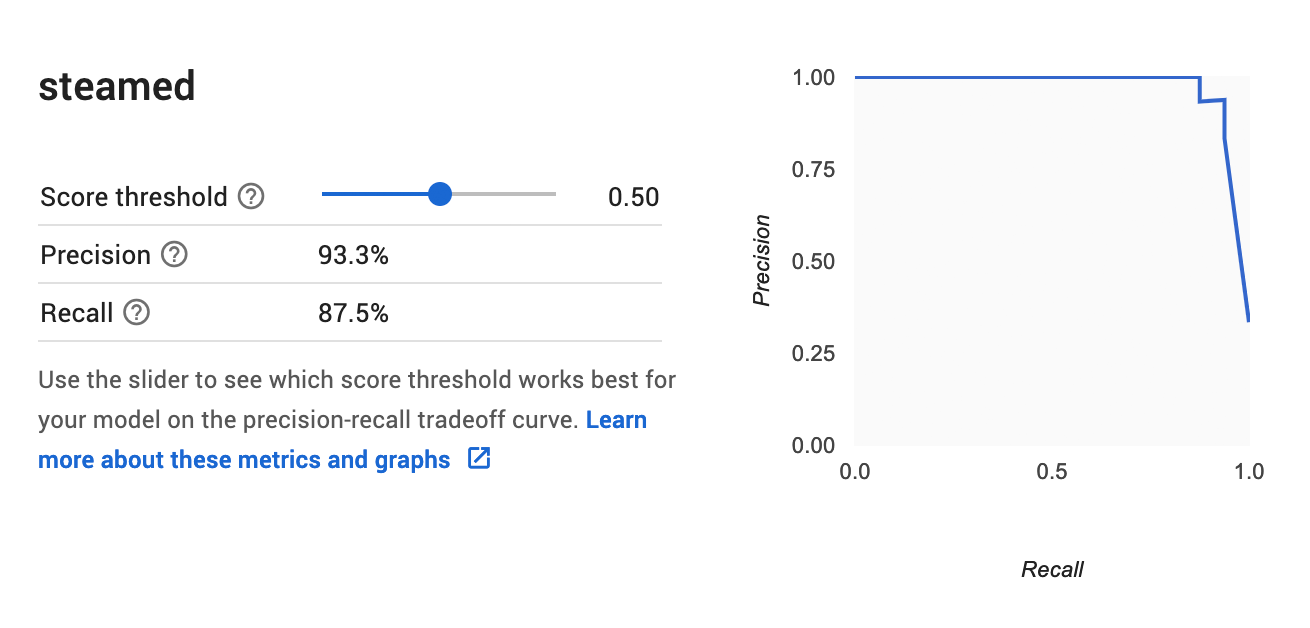
The metrics that we normally use in a classification task are: precision and recall.
For example, if we look at the steamed chicken class, Precision measure the predictive power, i.e. how many steamed chicken images that our model detects are correct. Recall then measures the ability to retrieve all steamed chicken images.
There is a slider where we can adjust the score threshold. In other words, if we set the threshold to 0.00, our recall will be 100% (as we can just say every image is “steamed” and we will not miss out any), but then the precision will be very poor.
Once you are done evaluating the performance, we can go to the fun part, to use our model to predict unknown chicken rice images.
You may take a photo of your own chicken rice or simply go to Google images and look for some pictures. These are the images that I used in my prediction test.

The result is pretty amazing and accurate right?
Conclusion – What’s next from here?
Although this is a simple example, but it is one that everybody can easily relate to. I have shown you how straightforward it is for us to build a computer vision based machine learning model.
In reality, we will need a better understanding about the features itself, and how to select good images that will be used as the training set based on the texture, color distribution, and lines and edges characteristics. AutoML vision is definitely a good starting point for someone with no technical background and would like to learn by building a machine learning model.
Try this for yourself and let me know if you’re able to do this in the comment section below! Also, if you found this tutorial useful, do share it with a friend who is learning machine learning and computer vision.
Excellent article.
Question :
If my precision score is low, Does the training model has an option where I can resume the training to improve my confusion matrix percentage since the model knows it wrongly predicted certain X-rays? or I need to re-do it from scratch?
Usually, we don’t, especially for a supervised learning model. That’s because the model we build is considered the optimized (i.e. best model) with the parameters and training set. It will only make sense if you make some changes to the training data or different features.