

Do you know what is the common thing between Google Search, Facebook, Alexa and the US President?
It’s “Natural Language Processing”
Natural Language Processing, or NLP in short, is a technique/field of study in computer science, where we study how to teach computers to understand the text.
What is a Natural Language?
A natural language is a language that has evolved naturally in humans through use and repetition without conscious planning. According to WorldAtlas, English is the most popular natural language in the world with 1.39 billion speakers, followed by Mandarin Chinese with 1.15 billion speakers.

Most popular natural language by number of speakers
As computers can only understand numbers, natural languages and texts need to be processed before we can use it for data mining or machine learning tasks. This process is called Natural Language Processing, or NLP in short. NLP allows us to teach the machines how to understand texts, or formally defined as:
Natural Language Processing is a field in Artificial Intelligence that enables machines with the ability to read and derive meaning from human languages.
Here are the 5-step process that involved in a standard NLP.
Tokenization
It is difficult for machines to understand the semantics and context of a document, a paragraph, or even a sentence as a whole. First, we utilize the tokenization process to break them to down their smallest semantic units call token.
For example, given a sentence “Dr. Lau is a data scientist“, we can break them down into six tokens using space as the separator. We also remove punctuations and symbols. This approach is suitable for any language that uses blank space as a separator. For languages that do not, such as Chinese, Japanese, and Thai, we will need to use a dictionary or apply external knowledge to split words into tokens.

Tokenization breaks an English sentence into tokens using space
Stop Word Removal
The next step after tokenization is to remove stopwords. Stopwords refer to terms that appear frequently in a natural language (e.g. is, am, a, in) but do not aid in understanding the meaning. Removing stopwords prevents high occurrence words from taking up space in our database and taking up the valuable processing time.

Common stopwords in the English language.
Stemming
In English, a verb can appear in many different forms. For example, in an article about Internet connection, the word “connect” may appear as: connects, connected, connecting, connection, and connections. Without any processing, machines will consider these words as five different words and calculate separately. Therefore, we will need to reduce these variants into their root form “connect“. This process is called stemming. Stemming reduce redundancy for words that have the same meaning, so that we can obtain an accurate calculation and increase the accuracy of subsequent tasks. Different stemming algorithm has their own rules, and a common stemmer for English is Porter Stemmer.
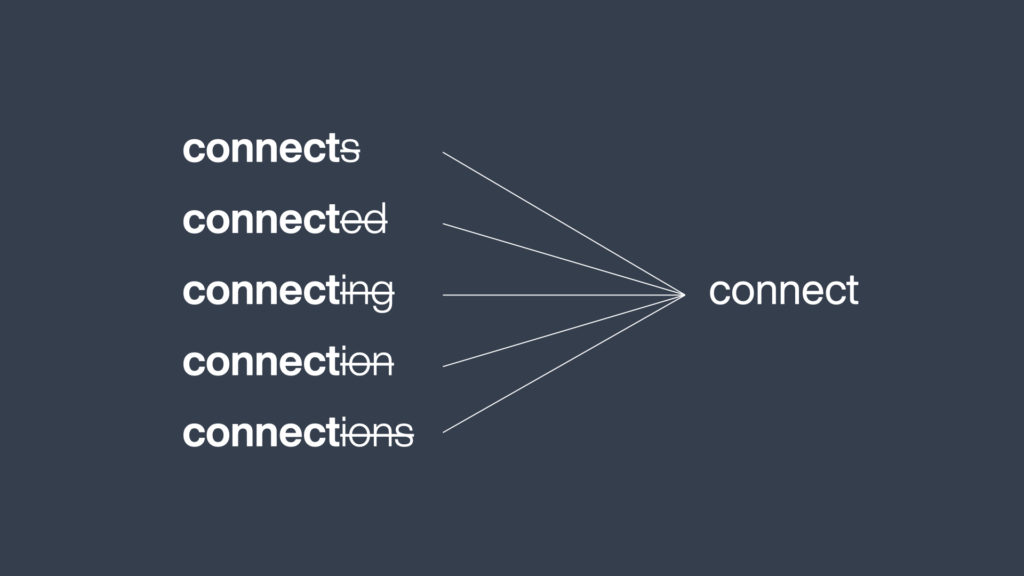
Stemming reduces word variations back to its root form
Lemmatization
In some cases, stemmer is unable to reduce word variations to its root form by simply chopping away the suffixes. Especially irregular verb pairs such as “begin, began“, “drank, drunk“, “eat, ate“, or words like “rats, mouse, mice“. We will need to utilize a dictionary or external knowledge to group inflected forms of a word together, and this process is called lemmatization.

Using lemmatization to group inflected forms of a word
Part-of-speech tagging
Lastly, we perform part-of-speech tagging, also known as POS tagging, to identify the role of a word in a sentence. This is based on the relationship and context with the surrounding words. Part of speech includes nouns, verbs, adverbs, adjectives, pronouns, prepositions, and other sub-categories.

Part of speech (or POS) tagging marks the role of a word in a sentence
Summary
Natural Language Processing is the fundamental tasks in all text processing tasks, in order to transform unstructured text into a form that computers understand. From this point on, we can use it to generate features and perform other tasks like named entity extraction, sentiment analysis, topic detection. With the help of deep learning algorithms, we can expect NLP to reach a level of advancement in the coming years, that make complex applications such as automatic translation, human-computer interaction, more possible.
Enjoyed reading this? do share with us your thoughts in the comment section below.
If you are interested to learn more about machine learning, AI, Big data, or if you aspire to become a data scientist, LEAD offers a complete Data Science course in Malaysia that is designed to equip you for a career in data science within 8 weeks.
What are some other NLP techniques do you use? Leave them in the comment section below.
Don’t forget to visit us on Facebook and subscribe to our YouTube channel for more interesting content too.
Hello, Amazing information shared and it’s very impressive and so much helpful for me. Keep it up and Thank you very much.:)